用 llamafactory-sft Skill 进行 llamafactory 微调
本文用一个教程式 Notebook 展示如何通过 llamafactory-sft skill,让智能体辅助完成一次 LlamaFactory SFT 微调流程。我们不会深入讲解所有训练参数,而是展示 skill 如何把一次微调任务拆成可确认、可追踪、可复现的步骤。
本教程使用一个轻量示例:基于 Qwen3.5-2B 模型,使用 LlamaFactory 内置数据集完成一次 LoRA SFT,并在训练后进行效果验证与模型导出。
1. 环境准备
本教程实验硬件与软件环境 ,本教程在AMD Radeon W7900上进行操作,同样的操作也适用于Nvidia GPU
| 项目 | 配置 |
|---|---|
| GPU | AMD Radeon PRO W7900 |
| ROCm | 7.2.1 |
| Agent | Cursor |
首先安装 LlamaFactory:
检查安装是否成功:
| |
如果输出 LlamaFactory 版本信息,说明环境准备完成。

本教程假设你已经在支持 skill 的智能体环境中打开了 LlamaFactory 仓库。llamafactory-sft skill 位于:
| |
2. 发起任务
当用户提出“用 LlamaFactory 做 SFT / 微调 / train a LoRA”等需求时,智能体会进入这个 skill 定义的工作流。除了自然语言触发,也可以在支持命令式调用的智能体里显式调用。不同 agent 的显式调用方式可能不同,以下写法仅作格式示例,实际以当前 agent 环境支持的语法为准。
触发 skill 有几种方式。可以直接用自然语言描述任务,也可以显式调用:
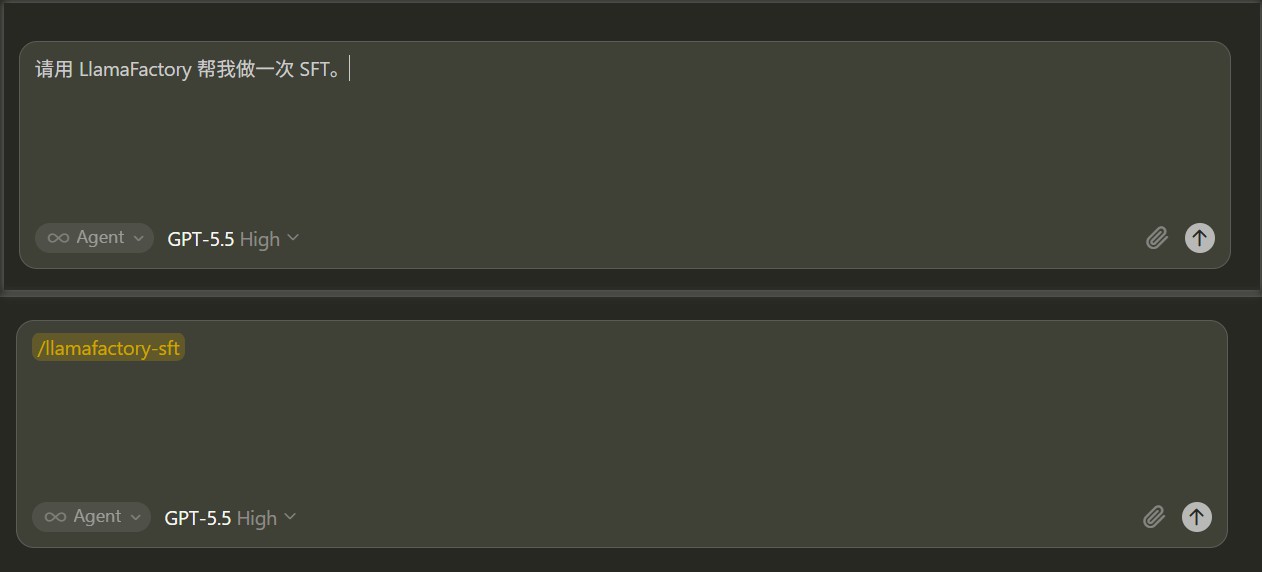
下面先给智能体一个自然语言任务。可以只做一个简单描述,skill 会继续向你确认模型、数据集、执行方式和微调类型等细节:
| |
也可以在一开始就写得更具体:
skill 的第一步不是立刻写配置,而是确认本次实验的整体形状。
3. Stage 0:确认整体流程
智能体会一次性确认三个关键分支:
| 问题 | 本教程选择 |
|---|---|
| 流程范围 | Full flow:训练、验证、导出 |
| 执行方式 | CLI |
| 微调类型 | LoRA |

如果用户一开始只说“请用 LlamaFactory 帮我做一次 SFT”,skill 会在这里以及后续过程中补齐这些信息,而不是默认选择。这样即使用户没有提前指定模型、数据集、CLI/WebUI 或 LoRA/Full/QLoRA,智能体也会通过交互把关键分支确认清楚。
确认后,智能体会在之后的每次回复顶部显示进度看板:
这个看板是 skill 里一个很实用的约束。训练任务往往会持续比较久,中间还会穿插模型下载、参数确认、日志轮询、导出等步骤。看板能让用户始终知道当前走到哪里。
3.1 分支一:SFT only 与 Full flow
如果在 Stage 0 选择 SFT only,skill 会只完成数据准备、模型准备、微调配置和训练。训练结束后,它会告诉你 checkpoint、日志和 loss 曲线的位置,然后结束流程
如果选择 Full flow(本教程示例),skill 会在训练完成后继续生成 infer.yaml、运行验证脚本,并根据 LoRA / QLoRA / Full 的不同方式生成导出配置。本教程后面的主线使用 Full flow。
3.2 分支二:如果选择 WebUI
如果在 Stage 0 选择 WebUI,skill 不会继续生成 CLI 训练 yaml 并自动启动训练,而是先完成数据、模型和 GPU 的准备,然后启动 LlamaFactory WebUI:
| |
如果是在远程服务器上运行,skill 会提示使用 SSH 端口转发,例如:
| |
随后在本地浏览器打开:
| |
WebUI 路线里,训练、验证和导出主要由用户在界面中点击完成。skill 的作用会变成“把已经确认的信息整理成 WebUI 填写建议”,例如:

也就是说,WebUI 分支更适合希望通过界面调整参数、观察训练曲线的用户;CLI 分支更适合希望让智能体完整执行、记录和轮询训练状态的用户。
4. Stage 1:准备数据集
本教程选择CLI 执行,更便于介绍
数据集选择本教程使用 LlamaFactory 内置数据集:
| |

智能体会读取 data/dataset_info.json,确认这些数据集已经存在。对于 identity 这类带模板变量的数据,skill 会提醒智能体询问是否需要替换 {{name}}、{{author}} 等变量,而不是直接使用默认占位符。

如果选择替换 identity 中的模板变量,智能体会把替换后的数据写入新的数据文件,例如 data/identity_custom.json,并在 dataset_info.json 中新增对应条目,例如注册为 identity_custom;原始 identity 文件不会被覆盖,也不会污染 LlamaFactory 自带数据集。实际文件名可以按实验名称调整。
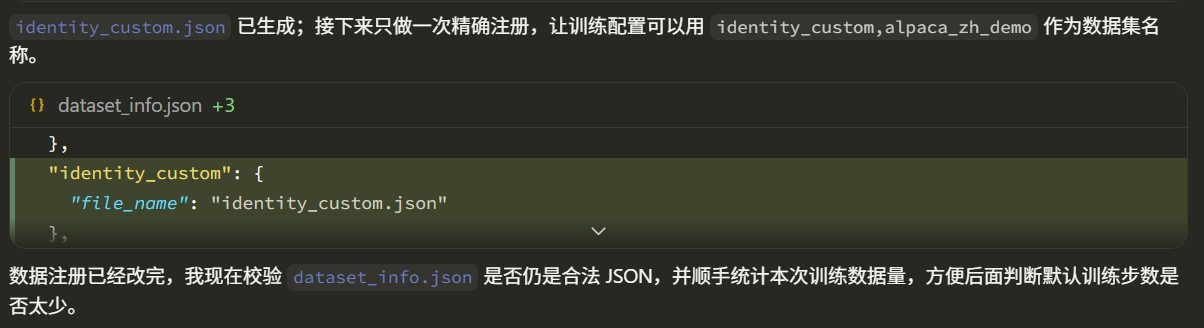
如果我们选择自定义数据,skill 会要求智能体先检查数据格式。LlamaFactory 常见的文本 SFT 数据格式包括 Alpaca 和 ShareGPT。
Alpaca 示例:
ShareGPT 示例:
如果数据不符合要求,skill 会让智能体先征求用户同意,再写入新的转换文件。它不会原地覆盖用户原始数据,也不会随意污染 LlamaFactory 自带的
data/*.json文件。
5. Stage 2:准备模型
本教程使用 Qwen3.5-2B 模型:
skill 要求智能体先从 LlamaFactory 自己的模型注册表中确认模型支持情况和默认模板,而不是凭经验猜测。相关信息在:
对于 Qwen3 模型,智能体会匹配对应的模型族和模板,并选择最接近的官方示例 yaml,例如:
| |
接着,智能体会检查本地是否已经有完整模型。如果模型不存在或缓存不完整,会询问下载源:
| 下载源 | 说明 |
|---|---|
| Hugging Face Hub | 可使用 Xet 加速 |
| ModelScope | 国内网络环境通常更稳定 |
| 让智能体决定 | 根据网络连通性自动选择 |
选择某个下载源开始下载后,智能体会监控下载速度,如果遇到下载速度慢的情况,会询问用户切换到另一个源

6. Stage 2.5:选择 GPU
训练前,skill 会让智能体检测 GPU (AMD 与 Nvidia GPU均可):
| |
如果只有一张空闲 GPU,就直接使用它。如果多张 GPU 空闲,智能体会询问使用单卡还是多卡
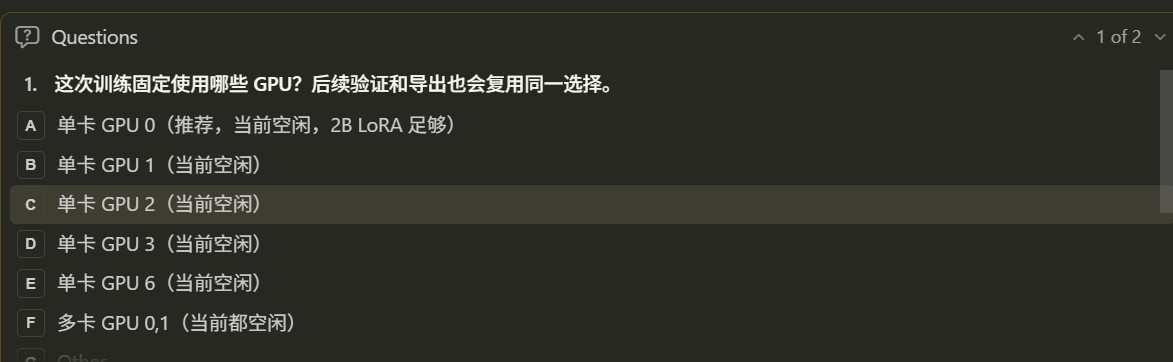
之后训练、验证、导出都复用同一个 GPU 选择。例如
ROCm 环境:
| |
NVIDIA 环境:
| |
这一步能避免一个常见问题:训练时用了一张卡,验证或导出时又重新探测,结果跑到了另一张忙碌的卡上。
7. Stage 3:生成训练配置
进入 CLI 路线后,skill 会让智能体从官方示例配置出发,尽量少改参数。
在写入 yaml 之前,智能体会先展示关键参数表:
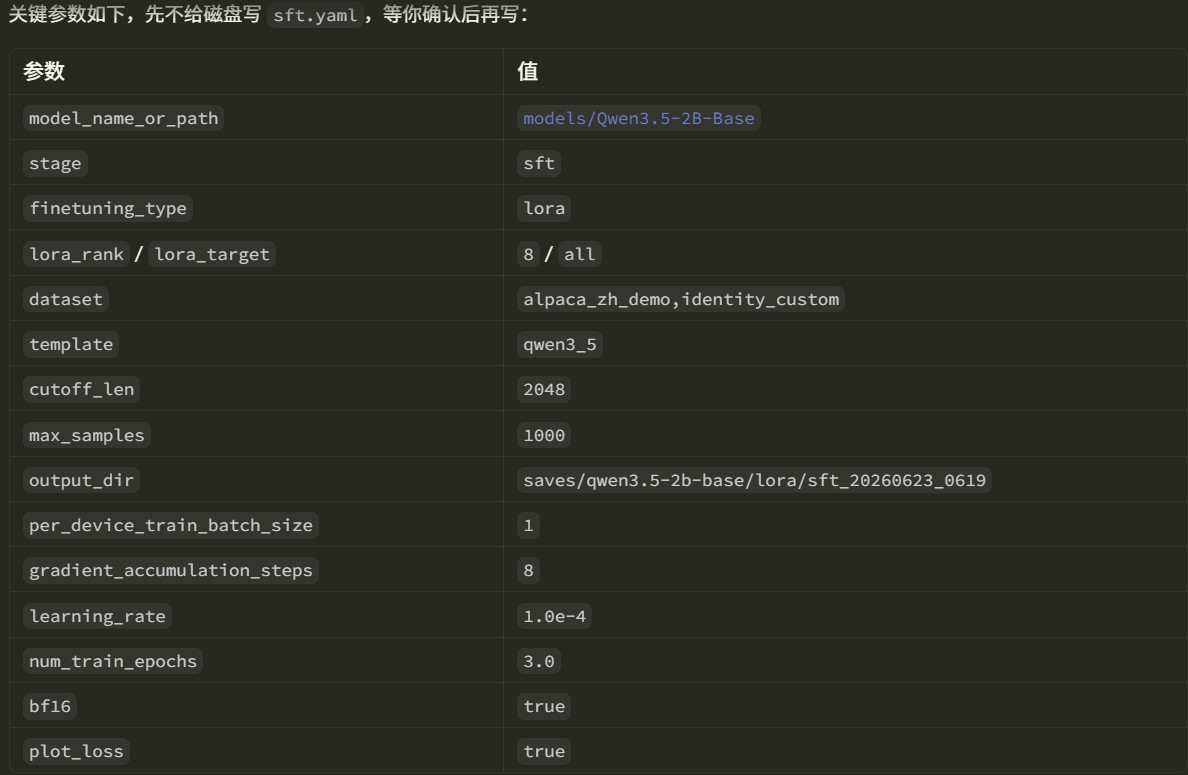
如果某些参数和官方示例不同,智能体还会展示差异表:
用户可以自定义修改想修改的参数,比如我们将template 修改为qwen3_nothink

用户确认后,智能体才会把配置写入 特定目录,这个目录专门存放本次实验的配置和日志,避免和模型权重、checkpoint 混在一起。
8. Stage 4:启动训练并跟踪 loss
训练配置确认后,智能体会后台启动训练:
| |
启动后智能体会继续轮询真实训练进程和日志。
状态汇报示例:

训练完成后,智能体反馈训练的一些基本信息,LlamaFactory 会在输出目录生成 loss曲线,可以查看训练loss
9. Stage 5:验证微调效果
完整流程会继续进入效果验证阶段。对于 LoRA 微调,推理配置需要同时包含 base model 和 adapter:
智能体会参考官方example的配置,生成对应yaml文件,展示并等待用户确认
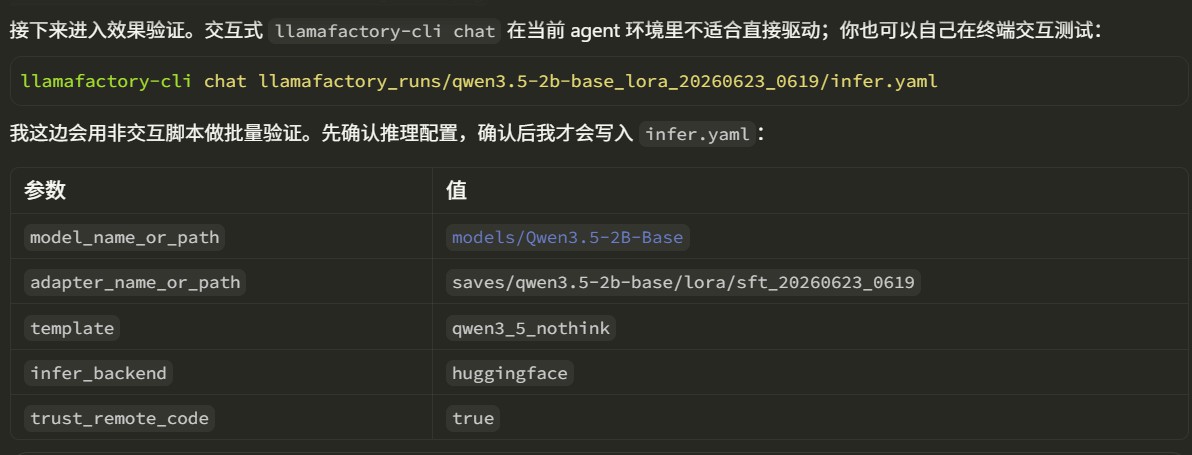
在智能体环境里,交互式 llamafactory-cli chat 通常不方便自动驱动,所以 skill 会生成一个非交互式的脚本,来进行效果验证,效果验证的query由用户指定

如果用户想自己交互式测试,可以运行llamafactory-cli 的命令,具体命令skill会展示给用户,只需要复制再终端中测试即可
10. Stage 6:导出模型
LoRA / QLoRA 的导出流程是把 adapter 合并进 base model,得到一个可独立加载的模型目录。
智能体会询问导出的目录配置
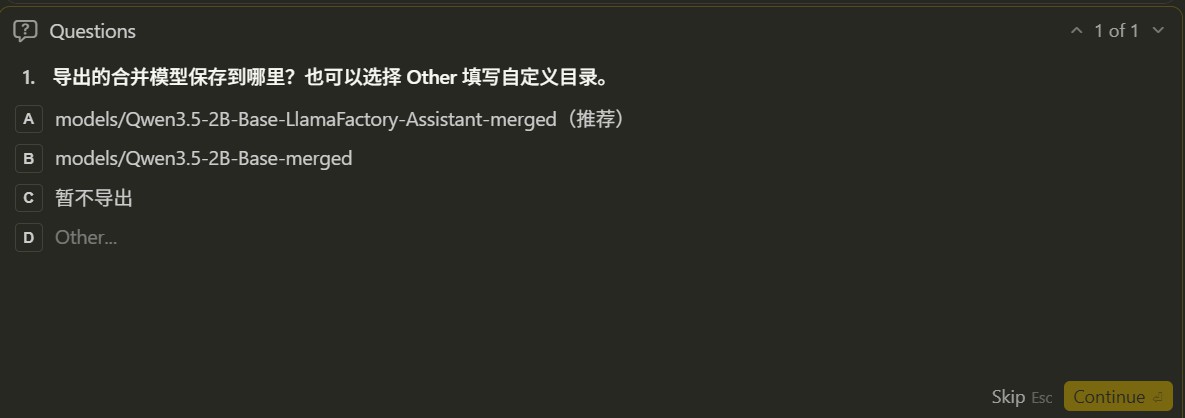
智能体会根据example中的示例以及用户指定的输出名称生成导出的yaml文件,示例如下
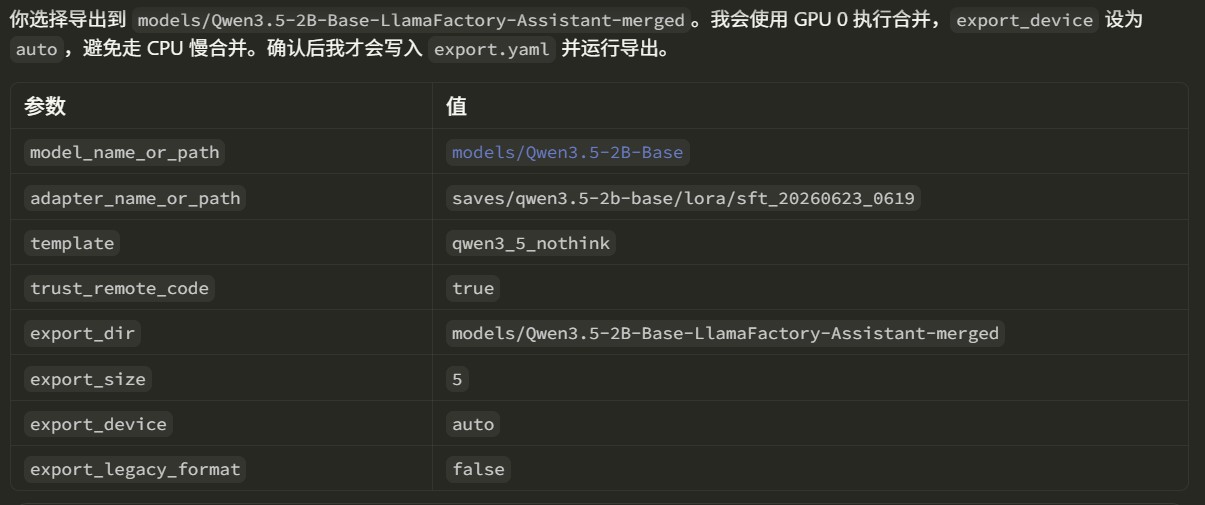
最终模型会保存到对应的目录中
如果是 Full 微调,则没有 adapter,也没有合并动作。skill 会要求智能体直接把 model_name_or_path 指向训练输出目录,并推荐导出到类似 models/<base_model>-sft 的目录。
11. 一次完整运行会产出什么
本教程的完整运行结束后,通常会得到以下文件和目录(以实际智能体提示为准):
llamafactory_runs/...保存本次实验的配置与日志;saves/...保存训练得到的 LoRA adapter 和 loss 曲线;models/...-merged保存合并导出的完整模型。
12. 小结
本教程在于演示 使用llamafactory-sft skill 通过agent来智能化的进行sft。通过这个 skill,用户不需要一次性记住所有细节,只需要用自然语言说明目标,智能体就能按阶段推进一次结构清晰的微调实验。对于刚开始使用 LlamaFactory 的用户,它能降低第一次跑通 SFT 的门槛;对于熟练用户,它也能减少重复排查配置细节的时间。